Less-popularised findings from the "estimating the reproducibility" paper @Eli_Finkel #SPSP2016 pic.twitter.com/8CFJMbRhi8— Jessie Sun (@JessieSunPsych) January 28, 2016
I don’t think we should be interpreting this correlation at
all, because it might very well be completely spurious. One important reason why correlations might be spurious is the
presence of different subgroups, as
introduction to statistics textbooks explain.
When we consider the Reproducibility Project (note: I’m a
co-author of the paper) we can assume there are two subsets, one subgroup consisting
of experiments that examine true effects, and one subgroup consisting of experiments
that examine effects that are not true. This logically implies that for one
subgroup, the true effect size is 0, while for the other, the true effect size
is an unknown larger value. Different means in subgroups is a classic case
where spurious correlations can emerge.
I find the best way to learn to understand statistics is
through simulations. So let’s simulate 100 normally distributed effect sizes
from original studies that are comparable to the 100 studies included in the
Reproducibility Project, and 100 effect sizes for their replications, and
correlate these. We create two subgroups. Forty effect sizes will have true
effects (e.g., d = 0.4). The original and replication effect sizes will be
correlated (e.g., r = 0.5). Sixty of the effect sizes will have an effect size
of d = 0, and a correlation between replication and original studies of r = 0.
I’m not suggesting this reflects the truth of the studies in the
Reproducibility Project – there’s no way to know. The parameters look sort of
reasonable to me, but feel free to explore different choices for parameters by
running the code yourself.

As you see, the pattern is perfectly expected, under reasonable assumptions, when 60% of the studies is simulated to have no true effect. With a small N (100 studies gives a pretty unreliable correlation, see for yourself by running the code a few times) the spuriousness of the correlation might not be clear. So let’s simulate 100 times more studies.

As you see, the pattern is perfectly expected, under reasonable assumptions, when 60% of the studies is simulated to have no true effect. With a small N (100 studies gives a pretty unreliable correlation, see for yourself by running the code a few times) the spuriousness of the correlation might not be clear. So let’s simulate 100 times more studies.
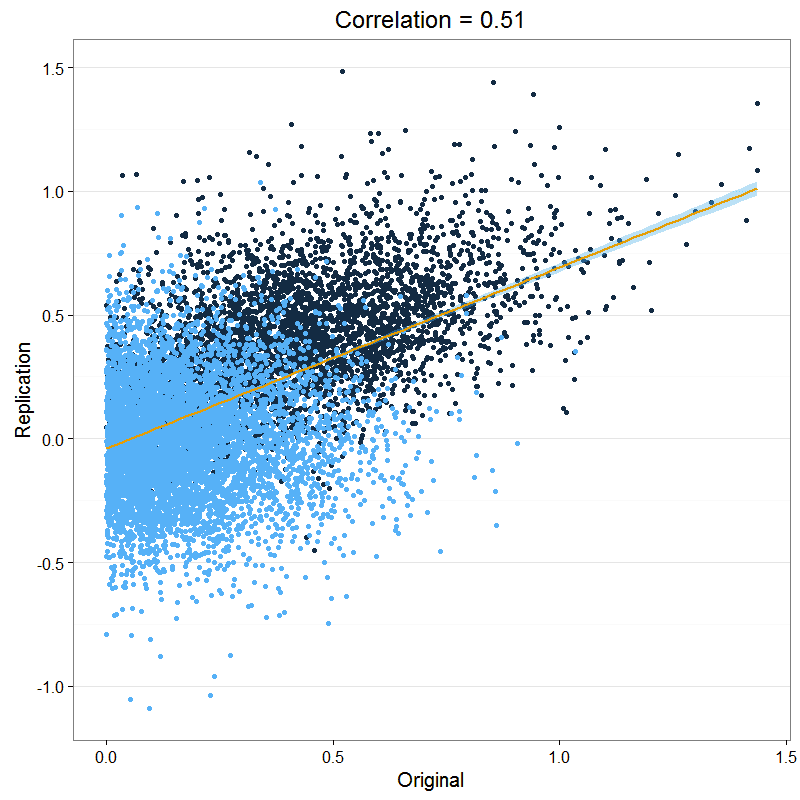
Now, the spuriousness becomes clear. The two groups differ in their means, and if we calculate the correlation over the entire sample, the r = 0.51 we get is not very meaningful (I cut off original studies at d = 0, to simulate publication bias and make the graph more similar to Figure 1 in the paper, but it doesn't matter for the current point).
So: be careful interpreting correlations when there are
different subgroups. There’s no way to know what is going on. The correlation
of 0.51 between effect sizes in original and replication studies might not
mean anything.
I'm not sure this is right. Your simulation assumes that the probability of a study belonging to the spurious vs. real subgroups is completely independent of the observed effect size in the original study. If that's true, your analysis goes through as stated--but only because you've already assumed your conclusion, as you're simply stipulating that the size of an observed effect in a sample can provide no indication of the true population value. This seems to me to be an untenable assumption: holding sample size constant, there is necessarily a positive relationship between population and sample effect sizes. Even if you allow for sample size variability, the relationship is likely to be positive, so why would you assume it's 0?
ReplyDeleteA separate issue is that it's not clear what the justification is for assuming that there are discrete sets of studies, one with all population effects == 0, and one with non-zero effects distributed N(x,y). This seems to me implausible in the extreme. What causal structure could the world possibly have that allows a large proportion of effects to be exactly zero, and a discrete and non-overlapping subset to be centered on a non-negligible value *other* than zero? Surely it's much more reasonable to model the population of studies as some continuous distribution, probably centered at or near zero, and perhaps with fat tails. But if you start from that prior, I'm not sure the simulation goes through, even if you ignore the issue raised above.
Hi Tal, what do you mean "Your simulation assumes that the probability of a study belonging to the spurious vs. real subgroups is completely independent of the observed effect size in the original study."? I am simulating a set of true effects, and a set of non-true effects. The 'spurious' refers to the correlation ACROSS these two groups, which is only caused by the mean difference. I think you misunderstood the simulation, or the point of the post? I'm not assuming 60% of the studies are not true in the RP - I'm showing that IF 60% of the studies have no effect, you can get the correlation reported in the OSC paper, and it might be spurious. You are right that a better simulation would put a distribution on the effect sizes that are true. I didn't, but it does not matter much for the point I'm making. Unless I'm misunderstanding your point.
DeleteI think I understand the simulation. And I think there are at least two big problems with it. The first problem is that your simulation starts from a different position from the actual Reproducibility Project. What your sim says is "if you assume an unbiased sample of studies, ~half drawn from a population of zero true effect, ~half drawn from a population that with large true effect, you can explain the collapsed correlation between T1 and T2 entirely by the difference in means." I'm happy to grant you this. But note that you're assuming all studies are included in analysis, without selection bias. Whereas this necessarily isn't true of the RP studies, because it's inconceivable that 40 out of 40 randomly selected effects with true population mean of zero would all be statistically significant. So in effect, you're assuming something to be true that can't be. Either there's selection bias in the RP studies, or it's simply not true that 40% of the population effects are actually zero.
DeleteYou can pick one, but you can't pretend both that the RP studies are unbiased, *and* that they still somehow all had large effect sizes. What you need to do is include the effect of selection bias in your simulation, for the 40% of null-effect studies. But if you do that, I'm pretty sure what you'll find is that your observed correlation goes down quite a bit, for the simple reason that the spurious effects regress to the mean, so they drag the T1-T2 correlation down. So you won't end up with a correlation of .5, you'll end up with something quite a bit smaller.
The second problem is that you're assuming some very wacky priors by setting up the simulation so that 40% of effects are drawn from a population where the true ES is 0 and 60% are truly large (d = 0.4) in the population. This state of affairs surely couldn't exist in the real world, because it would imply an absurdly sparse causal graph, where almost anything anyone could reasonably choose to study is, in the population, either (a) an effect of exactly 0, or (b) a generally large effect. Basically, you've decided that there is no such thing as a small effect, which seems untenable given that every meta-analytic estimate suggests that most effects psychologists study are actually quite small.
DeleteThe point is, the plausibility of the simulation's assumptions matters. Simply saying "look, there's a conceivable scenario under which this effect is explained by group differences" is not helpful, because that's true of every correlation anyone has ever reported. Unless you're arguing that we shouldn't interpret *any* correlations, it's not clear what we've learned. *Any* correlation might very well be spurious, or explained by non-linearities (e.g., being wholly due to one subgroup). So if you want to argue that we should worry about the case presented by your simulation (setting aside the first problem I raised above), you need to convince us that your model assumptions make sense. Otherwise the whole thing collapses into nihilism about statistical inference.
Notice that if you had made a different assumption, you would have ended up with a very different conclusion. For example, let's say you assume that studies in RP are unbiased. Then our best estimate of the true mean of the population of effect sizes should be the observed mean in RP. We would have no reason to assume that any studies in the original sample are false positives. Then your analysis wouldn't really make sense, because there would be only one group to worry about (of normally distributed ESs). Further, I would expect that you'd get different simulation results even if you kept the discrete groups but altered the parameters a bit. For example, if you assume that 10% of effects are 0 in the population, and 90% are drawn from N(0.3, 0.3), would you still want to argue that the correlation between T1 and T2 is spurious, just because a small fraction of effects are (by hypothesis) false positives? It seems unlikely.
The bottom line is, you're failing to consider how strong a prior you're assuming in order to make this argument seem worth worrying about. For one thing, to anyone who thinks a null of zero is just a useful abstraction (e.g., me), and that effects in the real world are never exactly zero, this analysis fails right away. If I reject your assumption that it makes any sense to think of discrete subgroups, and assume that there's only one population of true effect sizes, then I would have zero reason to ever worry about the "spuriousness" of my T1 - T2 correlation in the sense you seem to be suggesting. From my perspective, it's not spurious at all; saying that we're stably estimating effect sizes is exactly the right interpretation! I mean, it's true that if we observe a strong correlation between T1 and T2, it doesn't tell you what proportion of effects are non-zero (or 0.3, or any other value you care to choose)--but that would be a rather odd interpretation (and you wouldn't need your simulation to refute it, you could just trivially point out that the correlation coefficient is scaleless and nothing can be assumed about the means of the underlying variables).
About point 1: It's a minor issue. I used a very conservative difference between the 2 groups. The effects in the replication are probably much larger than d = 0.4. The bigger, the larger the overall correlation. Any bias you want to program in won't matter much.
DeleteI think the assumptions are very plausible, as long as you assume there is a set of true effect, and a set of non-true effects. I have used the average effect size in psych for the true effects, and non-true effects have a d = 0. The 40/60 split is based on subjective replication success. So that all sounds very plausible.
You seem to prefer some metaphysical viewpoint where all effects are true. That is a non-scientific statement, because it can never be falsified. So I don't think it is worth discussing. If you don't like 2 discrete subgroups, that's ok. All you need to do is accept there is a lower bound in what we can examine. The sample sizes in these studies make it impossible to find anything reliable smaller than say d = 0.2.
Indeed, my main point is this correlation is pretty much meaningless. I just reviewed a paper that said " Nevertheless, the paper reports a .51 correlation between original and replication effect sizes, indicating some degree of robustness of results"
Would you say that conclusion is justified? If so, how can it be justified if this correlation could (I think plausibly) be spurious?
To start with your last question: the statement you quote is unambiguously true. There is clearly some degree of robustness of results in the data; I don't see how anyone could deny this. It's true of your simulation as well, since you are, after all, putting in 40% large effects (by hypothesis). If you can find me a quote that says something like "this correlation of .51 suggests that even most of the effects that failed to replicate are robust in the population," I'll gladly agree that that's an incorrect interpretation. But as I pointed out above, to refute *that* interpretation, all you need to do is point out that the correlation coefficient is scale-free, and nothing can be inferred about the mean levels of the underlying variables. If that's your intended point, the simulation doesn't really add anything; you could have just pointed out that this correlation tells us only about variation in ES, and not about the actual values for any study.
DeleteAs for the justification for using discrete groups, I don't understand your statements that "The 40/60 split is based on subjective replication success" and that "The sample sizes in these studies make it impossible to find anything reliable smaller than say d = 0.2." I think you're forgetting about sampling error. It's true that if d = 0.2, each study will have low power to detect the effect. But that's precisely why you might end up with, say, only 40% of studies replicating, right? If an effect was non-zero but overestimated in the original sample, the probability of replication will be low, even though you would still expect T1 and T2 ES estimates to correlate. So we have (at least) two ways to explain what we're seeing in the RP data. You've chosen to focus on a world in which a large proportion of effects are exactly zero in the population, and a minority are very large, with essentially nothing in between. The alternative that I'm arguing is much more plausible is that there's a continuous distribution of effect sizes, with some large but most quite small (some can be exactly zero too if you like; that's fine too). A priori, that seems like a much more plausible state of affairs, as it doesn't assume some weird discontinuity in the causal structure of the world. To put it differently, do you really believe that if the RP study was repeated with n=10,000 for each effect, we would end up with 60% ~0 effects, and 40% d = ~.4 effects? I would bet any amount of money you like that we would see something much more continuous (though probably not normal-looking).
And as for my point 1: it absolutely _does_ make a difference. I wrote a small simulation similar to yours (code is here) that stipulates that effects must be significant at T1. The simulation also differs from yours in that the correlation between T1 and T2 is empirically determined based on the N and d's you specify, and not by a manually specified correlation. I think that's important, because the values you're entering for the correlation in your sim could be unrealistic or even impossible (e.g., if you have small samples, it's actually extremely hard to get a correlation of 0.5 between T1 and T2, unless the ESs are highly variable--which violates your simulation assumptions). You can play around with it if you like, but the short if it is that you can get just about any result you like out of the simulation just by playing with sample size, proportion of null studies, and the mean and sd of the Cohen's d distribution for the "real effect" group. You can get a correlation of 0.5 either by having highly variable true ESs, or by having parameters like those you pick (but only with much larger samples--n = 20 doesn't work, you never get values about .2 or .3).
Basically, I think your argument amounts to saying "there is a world in which this result would not be very interesting", and concluding that we should therefore not trust it. But as I've pointed out twice now, the same logic could be used to discount literally *any* correlation. Suppose I report a .5 correlation between age and brain volume. You could say, "look, it's entirely possible that the correlation is driven solely by what happens after age 70, and the association is flat until 70--which would result in a different interpretation." Well, you might be right, but surely it's incumbent on you to provide evidence for your concern, and not on me to stop interpreting every correlation coefficient I compute until I can rule out every possible non-linearity. Basically, you need to justify your assumption that 60% of the effects studied in RP are actually 0 in the population (and, per my sim, you probably also have to assume more power than the RP studies are likely to have had). Unless someone already believes your prior (in which case, there's nothing left to convince them of anyway), your simulation isn't doing anything more than saying "you can't be certain this correlation means what you think it means." Okay, but so what?
DeleteYour simulation is probably better, and I wanted to use the simulation as an illustration, there is too much unknown to be evidential. You acknowledge the correlation can come from a difference in means between subgroups, so our only disagreement is how big the group of null effects is. I don't want to bet it's 60% but I think there is a subgroup large enough. The OSC has a commentary in press with additional data that agrees (still embargo, I'm not a co-author). Maybe another issue is how much others are reading into the correlation. If they had thought that the correlation implies many nonsignificant effects are still true, after this exchange they might acknowledge it is unclear what the correlation means and it can fit any prior.
DeleteFair enough. But with respect to your last point, I still maintain that a simpler and more compelling rebuttal to anyone who draws the interpretation you suggest is that a standardized correlation coefficient tells you nothing about the values of the underlying observations. If I tell you that the correlation between brain volume and age is 0.5, you have no basis for concluding that "brain integrity must therefore be okay in a large proportion of the sample". So that interpretation is wrong on its face, independently of what else one happens to think is true of the world.
DeleteAgreed.
DeleteI am also not sure this is right. I'm pretty sure its not actually.
ReplyDeleteWhat about effects that are true but operationalized poorly, or effects that are false but due to a flaw in the theory and operationalization it turns out true? Or, say studies that were actually different in the replication than in the original? there seem to be much more to say, but I know you wont learn! :D
All you are saying is not relevant to the point I am making.
DeleteWell, you are trying to dichotomize the data, and that, as anyone with proper methods experience knows, is not quite ideal! :D
DeleteThough you are only 20% statistician! :D
What do you mean by spurious? Evidently, the observed effect sizes in the original and the replication study are not causally related because they are a function of the true effect size in the population. This pattern of correlation is typically called spurious so to say that the relationship is spurious is not invalidating the importance of finding a correlation between A and B which shows that there is variation in the common cause C.
ReplyDeleteVariation in the common cause C, the population effect sizes, can take any form. Some of the true effect sizes may be zero. As long as some are non-zero, we expected a correlation between the observed effect sizes.
Ergo, we can conclude from the correlation that (a) not all population effect sizes are zero, and (b) that there is variability in the population effect sizes.
I agree Uli - but that's not how they are interpreted (see slide in the blog). The correlation is interpreted as if it contains meaning about the truth of the effect size estimates in the original studies, the idea being 'if they correlate 0.51, they are pretty strongly related, so that is hopeful for the 60 non significant studies'. My point is the correlation can occur easily with 60 effects that are not true, and 40 effects that are true.
DeleteI really don't think this shows anything at all. Yes, if you assume there are two subgroups with different means, then there will be a correlation if you ignore those two subgroups (even if there is there is no correlation within each group).
ReplyDeleteYou write: "There's no way to know what is going on. The correlation of 0.51 between effect sizes in original and replication studies might not mean anything." Or it may mean that the correlation reflects a true relationship between the effects in the original studies and the replications. If I would start out with that assumption, then simulate some data that way, then I can also get that 0.51 correlation. But that doesn't demonstrate that my assumption is any more correct than the one you are making. This is purely tautological.
The assumption that there are two subgroups follows logically from the data, as long as you accept the possibility some of there are null effects. Given the sample sizes on average, most true effects are at least somewhat larger than 0 or there would be no power. So the assumption of two subgroups, one with a true effect larger than 0, seems reasonable to me.
DeleteAppreciate the clean simulation, though it is far from Simpson's paradox or the like. I also don't think the simulated data match the reproducibility data well because by design you have a lot of points clustered around “Original” Effect Size d=0 while
ReplyDeletein the reproducibility paper there are very few in that range, though there is a cluster around d=0.2 or so. Thus, although you get the similar correlation, that is not enough to conclude you are simulating the original data well, so your conclusion that you could get the correlation of ~0.5 by the two-subgroup scenario you desribe, while true, is not relevant to the actual results. It is simply a mere possibility of what is happening with all (?) experiments perhaps. To make your subgroup scenario relevant to the reproducibility paper, you should actually fit a mixture model on the reproducibility results and examine fit.
Very related point: in your simulation, the “Original” effect size is not really original, but a sample from the true effect size. In the reproducibility paper, the “Original” is the *observed* effect size, where the true is unknown, of certain experiments of interest where usually these d > 0.15 or so. Thus, to adequately simulate that data, you need to censor (in statistical sense) your d=0 subgroup, at which point it will be clear your “spuriousness” as indicated by separation of the two subgroups would not nearly be so clean.
censor the subgroup meaning remove all or most values with d < .15 from the d=0 subgroup, to make it look like the actual reproducibility dataset.
Delete+1; This was basically the point I made above as well. I posted another simulation here that censors all "original" effects based on statistical significance, and the short of it is that it is indeed much harder to get results like Daniel's unless you assume a much larger sample size per study. (And you can also get the same correlation in a variety of other ways--notably, by having highly variable true ESs, which I suspect is an assumption most people will be more comfortable with.)
DeleteI also commented on Twitter, but wasn't able to fit my comment into the character limit.
ReplyDeleteI don't think the results of this simulation necessarily imply that the correlation isn't meaningful. Could be could not be, but you've demonstrated it's certainly questionable, given that the correlation could arise for a couple very different reasons.
I largely agree with your conclusion that the correlation has been interpreted incorrectly. But I think it could be interpreted meaningfully, even if the simulation accurately accounts for why the correlation was observed. My thinking is that if we interpret the r = .51 as if it were converted into a logistic regression (with replicate vs. not as a dichotomous outcome regressed on original effect size), it would lead to the conclusion that large effect sizes were more likely to replicate than small effect sizes. This would indicate we should be more skeptical of small effect sizes, because the smaller effect sizes were more likely to fall in the "not replicated" category. This is still useful and I would argue meaningful information, but it would suggest we should actually be more skeptical of small effect sizes, whereas the r = .51 could lead one to come to the completely opposite conclusion, that this correlation is actually good news for small effect sizes.