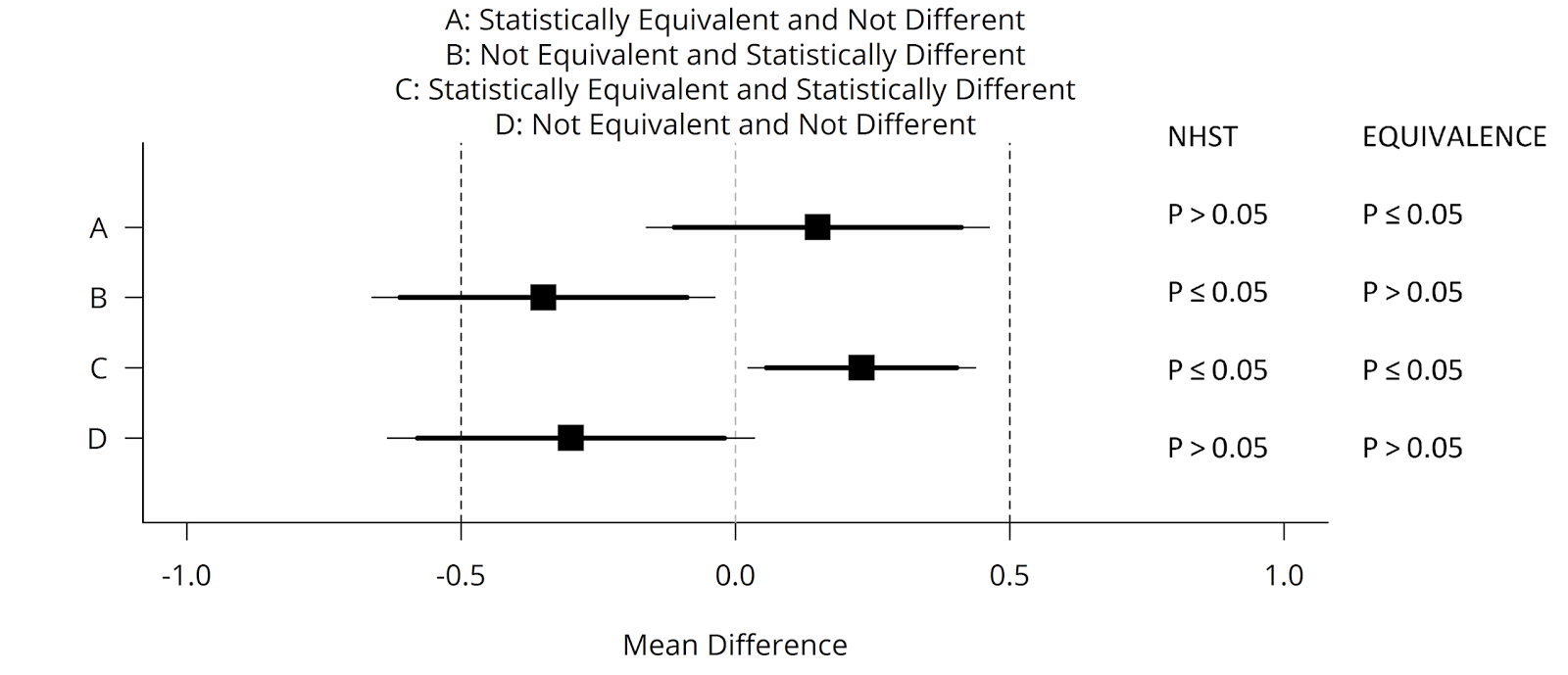
One of the challenges of trying to get
people to improve their statistical inferences is access to good software.
After 32 years, SPSS still does not give a Cohen’s d effect size when researchers
perform a t-test. I’m a big fan of R nowadays, but I still remember when it I
thought R looked so complex I was convinced I was not smart enough to learn how
to use it. And therefore, I’ve always tried to make statistics accessible to a
larger, non-R using audience. I know there is a need for this – my paper on
effect sizes from 2013 will reach 600 citations this week, and the spreadsheet
that comes with the article is a big part of its success.
So when I wrote an article about thebenefits of equivalence testing for psychologists, I also made a spreadsheet.
But really, what we want is easy to use software that combines all the ways in
which you can improve your inferences. And in recent years, we see some great
SPSS alternatives that try to do just that, such as PSPP, JASP, and more recently, jamovi.
Jamovi is made by developers who used to
work on JASP, and you’ll see JASP and
jamovi look and feel very similar. I’d recommend downloading and installing
both these excellent free software packages. Where JASP aims to provide
Bayesian statistical methods in an accessible and user-friendly way (and you
can do all sorts of Bayesian analyses in JASP), the core aim of jamovi is wanting to make software that is ‘“community driven”, where anyone can
develop and publish analyses, and make them available to a wide audience’. This
means that if I develop statistical analyses, such as equivalence tests, I can
make these available through jamovi for anyone who wants to use these tests. I
think that’s really cool, and I’m super excited my equivalence testing package
TOSTER is now available as a jamovi module.
You can download the latest version of jamovi
here. The latest version at the time of writing is 0.7.0.2. Install, and
open the software. Then, install the TOSTER module. Click the + module button:

Install the TOSTER module:

And you should see a new menu option in the
task bar, called TOSTER:

To play around with some real data, let’s
download the data from Study 7 from Yap et al,
in press, from the Open Science Framework: https://osf.io/pzqj2/.
This study examines the effect of weather (good vs bad days) on mood and life
satisfaction. Like any researcher who takes science seriously, Yap, Wortman,
Anusic, Baker, Scherer, Donnellan, and Lucas made their data available with the
publication. After downloading the data, we need to replace the missing values
indicated with NA with “” in a text editor (CTRL H, find and replace), and then
we can read in the data in jamovi. If you want to follow along, you can also
directly download the jamovi file
here.
Then, we can just click the TOSTER menu,
select a TOST independent samples t-test, select ‘condition’ as condition, and
analyze for example the ‘lifeSat2’ variable, or life satisfaction. Then we need
to select an equivalence bound. For this DV we have data from approximately 117
people on good days, and 167 people on bad days. We need 136 participants in
each condition to have 90% power to reject effects of d = 0.4 or larger, so let’s
select d = 0.4 as an equivalence bound. I’m not saying smaller effects are not
practically relevant – they might very well be. But if the authors were
interested in smaller effects, they would have collected more data. So I’m
assuming here the authors thought an effect of d = 0.4 would be small enough to
make them reconsider the original effect by Schwarz & Clore (1983), which
was quite a bit larger with a d = 1.38.
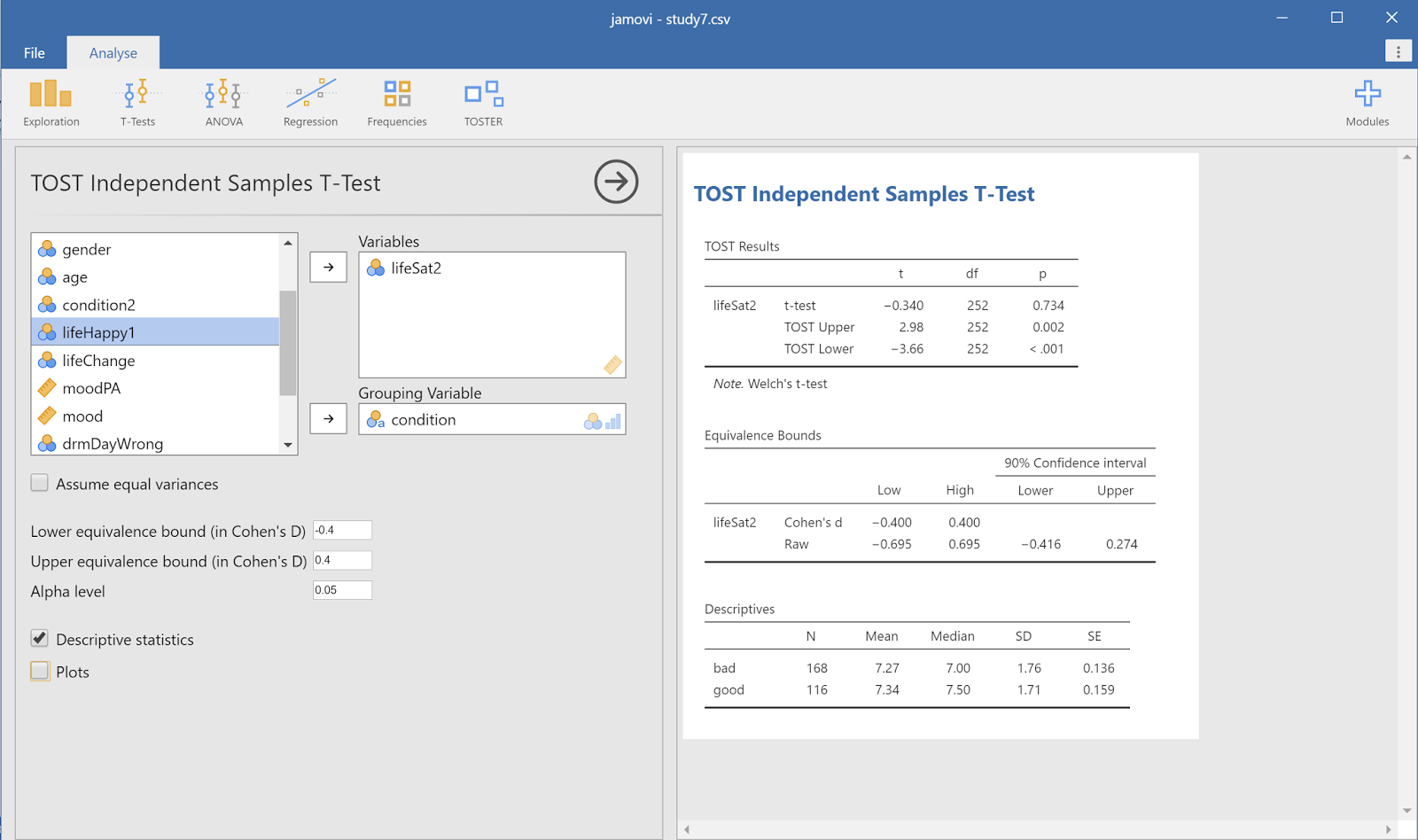
In the screenshot above you see the analysis and
the results. By default, TOSTER uses Welch’s t-test, which is preferable over
Student’s t-test (as we explain in this recent article), but if
you want to reproduce the results in the original article, you can check the
‘Assume equal variances’ checkbox. To conclude equivalence in a two-sided test,
we need to be able to reject both equivalence bounds, and with p-values of
0.002 and < 0.001, we do. Thus, we can reject an effect larger than d = 0.4
or smaller than d = -0.4, and given these equivalence bounds, conclude the
effect is too small to be considered support for the presence of an effect that
is large enough, for our current purposes, to matter.
Jamovi runs on R, and it’s a great way to
start to explore R itself, because you can easily reproduce the analysis we
just did in R. To use equivalence tests with R, we can download the original
datafile (R will have no problems with NA as missing values), and read it into
R. Then, in the top right corner of
jamovi, click the … options window, and check the box ‘syntax mode’.

You’ll see the output window changing to
the input and output style of R. You can simply right-click the syntax on the
top, right-click, choose Syntax>Copy and then co to R, and paste the syntax
in R:

Running this code gives you exactly the
same results as jamovi.
I collaborated a lot with Jonathon Love on
getting the TOSTER package ready for jamovi. The team is incredibly helpful, so
if you have a nice statistics package that you want to make available to a huge
‘not-yet-R-using’ community, I would totally recommend checking out the developers hub and getting started! We are seeing
all sorts of cool power-analyses
Shiny apps, meta-analysis spreadsheets,
and meta-science tools like p-checker
that now live on websites all over the internet, but that could all find a good
home in jamovi. If you already have the R code, all you need to do is make it
available as a module!
If you use it, you can cite it as: Lakens, D. (in press). Equivalence tests: A practical primer for t-tests, correlations, and meta-analyses. Social Psychological and Personality Science. DOI: 10.1177/1948550617697177
If you use it, you can cite it as: Lakens, D. (in press). Equivalence tests: A practical primer for t-tests, correlations, and meta-analyses. Social Psychological and Personality Science. DOI: 10.1177/1948550617697177